ASISTENTE PERSONAL-IA BMO
Proyecto seytrma2526g10 · URJC Autores Diego García García, David García Rodríguez, Álvaro Monge Pérez e Iván Navarro Álvarez.
Este documento recoge el diseño, desarrollo e implementación de BMO, un asistente robótico de escritorio de bajo coste capaz de mantener conversaciones naturales en lenguaje hablado. El sistema integra un modelo de lenguaje de última generación (Google Gemini 1.5 Flash) con una interfaz física dotada de expresividad visual mediante una pantalla LCD gráfica.
El reto técnico principal abordado consiste en superar las limitaciones de procesamiento y memoria de un microcontrolador básico (Arduino Uno) sin renunciar a las capacidades de un asistente conversacional moderno. La solución adoptada es una arquitectura distribuida de tipo Serial Bridge que separa la capa cognitiva (ejecutada en el ordenador) de la capa sensorial y de actuación (ejecutada en el microcontrolador), comunicadas mediante protocolo serie sobre USB.
El presupuesto total del prototipo se mantiene por debajo de los 15 €, demostrando que es posible democratizar el acceso a interfaces hombre-máquina avanzadas mediante la combinación inteligente de hardware modular de bajo coste y servicios de IA en la nube.
Palabras clave: Inteligencia Artificial conversacional, Procesamiento de Lenguaje Natural, Arduino, Python, Gemini 1.5 Flash, arquitectura Serial Bridge, robótica educativa, interfaz hombre-máquina.
1. Introducción y Visión General
1.1. Contexto y motivación
La popularización de los modelos de lenguaje de gran tamaño (LLM) ha transformado la concepción de los asistentes virtuales: hoy es posible mantener conversaciones contextualmente coherentes con un nivel de naturalidad inalcanzable hace pocos años. Sin embargo, la mayor parte de estos asistentes residen exclusivamente en pantallas (móviles, ordenadores o altavoces inteligentes), lo que limita su carácter empático y su integración en el entorno físico del usuario.
BMO surge como respuesta a esa carencia: un asistente físico, expresivo y de bajo coste que combina la potencia cognitiva de un LLM con un cuerpo capaz de escuchar, mirar y responder mediante voz y expresiones faciales animadas.
1.2. Objetivos del proyecto
- Objetivo principal: diseñar e implementar un robot de escritorio capaz de mantener conversaciones naturales mediante una arquitectura distribuida que combine hardware embebido de bajo coste con servicios de IA en la nube.
- Desarrollar una interfaz física empática que reaccione visualmente al diálogo mediante expresiones faciales sincronizadas con la voz.
- Demostrar la viabilidad técnica y económica de un asistente conversacional físico con un presupuesto inferior a 15 €.
- Implementar una arquitectura modular y escalable que permita la sustitución del modelo de IA o de los componentes físicos sin reescribir el sistema.
1.3. Alcance y enfoque técnico
Para superar las estrictas limitaciones de memoria SRAM y capacidad de cómputo del microcontrolador, el proyecto adopta una arquitectura denominada Serial Bridge (Puente Serial). Esta técnica delega el procesamiento intensivo (reconocimiento de voz, inferencia del modelo y síntesis de habla) a un ordenador central, reservando al hardware robótico las funciones de captación sensorial y representación visual y sonora.
Esta separación de responsabilidades permite mantener el coste del prototipo físico al mínimo y, simultáneamente, beneficiarse de la potencia de cálculo y los servicios cloud de última generación.
2. Arquitectura del Sistema
2.1. Visión general
El ecosistema BMO se articula en dos bloques funcionales que operan de forma asíncrona y se sincronizan continuamente mediante un canal serie a 9.600 baudios sobre USB:
- Cuerpo (Frontend): una placa Arduino Uno responsable de la captación de eventos acústicos y de la representación visual de las expresiones faciales en la pantalla LCD.
- Cerebro (Backend): un programa Python ejecutado en un ordenador convencional que realiza el reconocimiento del habla, consulta al modelo de lenguaje, sintetiza la respuesta hablada y orquesta las animaciones del cuerpo.
Esta segregación funcional sigue el patrón clásico cliente-servidor adaptado al ámbito embebido, y garantiza que los componentes de bajo nivel (sensórica y actuación) permanezcan desacoplados de la capa cognitiva.
2.2. El Cuerpo: Frontend en Arduino (C++)
El microcontrolador ejecuta una máquina de estados finita que coordina dos rutinas principales:
- Monitorización activa: en estado de reposo, el sistema muestrea el micrófono de manera continua. Cuando detecta un pico de presión sonora superior a un umbral configurable, envía la señal RUIDO_DETECTADO al backend para activar el ciclo de conversación.
- Reacción visual: tras la activación, el Arduino queda a la espera de los códigos de comando enviados por el PC (‘I’ inactivo, ‘L’ escuchando, ‘T’ hablando, ‘S’ silencio) y, mediante la librería LiquidCrystal, anima en tiempo real expresiones faciales construidas con caracteres ASCII personalizados sobre la pantalla LCD gráfica.
2.3. El Cerebro: Backend en Python 3.12
El backend está estructurado de forma modular en torno al fichero main.py, que actúa como director de orquesta del flujo conversacional. Sus responsabilidades principales son:
- Mantener una escucha permanente sobre el puerto serie a la espera de eventos generados por el Arduino.
- Activar el micrófono del PC mediante la librería speech_recognition y transcribir el audio capturado a texto.
- Enviar el texto transcrito al modelo Gemini 1.5 Flash a través de google-generativeai y recibir la respuesta del LLM.
- Sintetizar localmente la respuesta hablada mediante pyttsx3.
- Coordinar las animaciones faciales devolviendo al Arduino los códigos de comando vía pyserial, manteniendo la sincronía labial entre voz y boca animada.
2.4. Comunicación entre subsistemas
El canal serie a 9.600 baudios resulta suficiente para transportar los pequeños paquetes de control que intercambian ambos extremos. El protocolo es deliberadamente simple: cada mensaje consiste en un único carácter ASCII que actúa como token de estado o evento, lo que minimiza la latencia y el riesgo de tramas malformadas. Esta sencillez es deliberada y facilita la depuración en cualquier monitor serie convencional.
3. Hardware, Conexiones y Presupuesto
3.1. Esquema de conexiones
La integración hardware se ha realizado sobre una protoboard estándar, manteniendo el cableado lo más corto posible para reducir interferencias electromagnéticas. Los principales módulos del sistema y sus conexiones son los siguientes:
- Pantalla GLCD 128×64 (Type B): comunicación paralela mediante los pines digitales D2 a D9. El pin Vo (control de contraste) se conecta al cursor de un potenciómetro de 10 kΩ que permite el ajuste fino del contraste.
- Módulo de micrófono MAX4466: alimentación a 3,3 V (en lugar de 5 V) para minimizar el ruido eléctrico inducido por la fuente. Tierra común con el Arduino y salida analógica conectada al pin A0.
- Amplificador PAM8403 + altavoz: alimentación desde la línea de 5 V del Arduino. La señal de audio procedente del PC se inyecta mediante un cable jack de 3,5 mm pelado (malla a GND, canal L/R a la entrada del módulo) y la salida amplificada se conecta directamente al altavoz de 8 Ω.
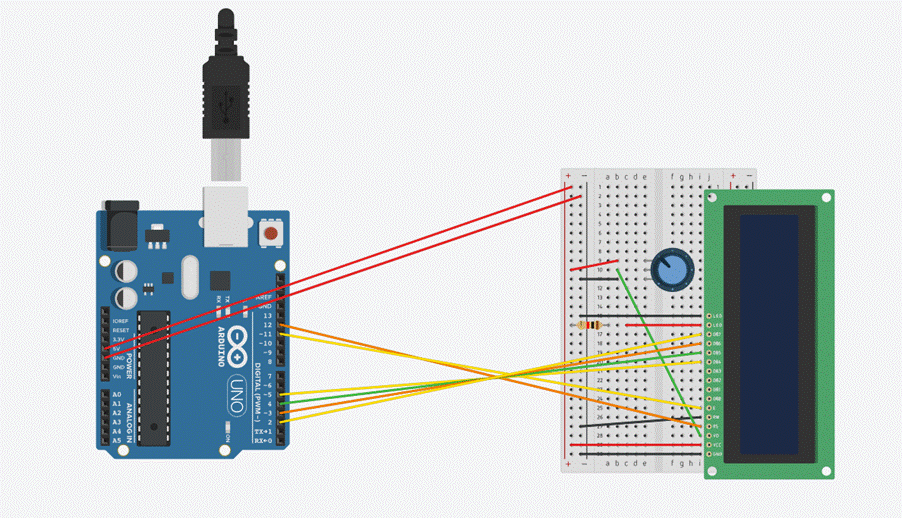
(En el tinkercad no estaba ni el micrófono ni el amplificador por eso no sale en el diseño en tinkercad)
3.2. Desglose de costes
La siguiente tabla recoge el presupuesto detallado del prototipo. Los componentes marcados como “KIT” forman parte del kit docente disponible y no han generado coste adicional para el grupo:
| Componente | Especificación | Coste aprox. (€) |
| Microcontrolador | Arduino Uno R3 (clon/kit) + protoboard | 0 € — KIT |
| Visualización | Pantalla GLCD 128×64 (Pinout Type B) | 0 € — KIT |
| Entrada de audio | Módulo de micrófono MAX4466 (pack de 3) | 6,99 € |
| Salida de audio | Amplificador PAM8403 (pack de 3) | 7,99 € |
| Componentes pasivos | Potenciómetro 10 kΩ, resistencias, cables jumper | 0 € — KIT |
| Altavoz | Altavoz 8 Ω (aportación de un integrante del grupo) | 0 € |
| TOTAL | Coste efectivo del prototipo | ≈ 15 € |
El coste efectivo asumido por el grupo se sitúa por tanto en aproximadamente 15 €, lo que confirma una de las hipótesis de partida del proyecto: la viabilidad de un asistente robótico funcional con un presupuesto al alcance de cualquier estudiante.
4. Implementación e Integración de IA
4.1. Fases metodológicas
El desarrollo del proyecto se ha estructurado en cuatro fases secuenciales que han permitido validar de forma incremental cada subsistema antes de proceder a la integración global:
- Fase 1 — Montaje físico: ensamblaje de los componentes sobre protoboard, soldadura de pines en módulos delicados y validación de continuidad eléctrica.
- Fase 2 — Programación frontend (Arduino): implementación de la máquina de estados, calibración del umbral del micrófono y diseño de las expresiones faciales en la pantalla LCD.
- Fase 3 — Desarrollo backend (Python): configuración del entorno virtual, integración con la API de Gemini, implementación del reconocimiento y síntesis de voz, y pruebas unitarias de cada módulo.
- Fase 4 — Sincronización (Serial Bridge): integración de ambos extremos, definición del protocolo de comunicación y ajuste fino de la latencia y la sincronía boca-voz.
4.2. Selección del modelo de lenguaje
Tras evaluar varias alternativas (modelos locales tipo Llama, GPT-4o vía OpenAI y la familia Gemini de Google), se ha optado por Gemini 1.5 Flash a través de su API oficial. La elección obedece a tres criterios principales:
- Latencia: la versión Flash está específicamente optimizada para respuestas en tiempo real, lo cual resulta crítico en una aplicación conversacional.
- Coste: la cuota gratuita ofrecida por Google Cloud cubre con holgura el volumen de inferencias de un prototipo académico.
- Calidad multilingüe: el modelo presenta un rendimiento excelente en español, lengua nativa del proyecto.
4.3. Flujo de procesamiento en tiempo real
El ciclo conversacional completo se desarrolla en cinco etapas encadenadas, ejecutadas en menos de dos segundos en condiciones normales de red:
- El micrófono del PC capta la voz del usuario y la librería speech_recognition la transcribe a texto.
- El texto se concatena con un system prompt predefinido (“Eres BMO, un robot asistente amigable…”) que fija la personalidad y las restricciones del asistente.
- La consulta se envía a Gemini 1.5 Flash, que devuelve la respuesta textual en el contexto de la conversación.
- El backend sintetiza el audio mediante pyttsx3 y comienza la reproducción local.
- De forma simultánea, se envían al Arduino los comandos de animación que mueven la “boca” en la pantalla LCD, manteniendo la ilusión de sincronía labial mientras dura la voz sintetizada.
5. Problemas Técnicos y Soluciones
A lo largo del desarrollo se han enfrentado obstáculos significativos, tanto de hardware como de software. La siguiente tabla recoge los más relevantes junto con la solución finalmente adoptada:
| Problema | Descripción | Solución adoptada |
| Limitación de hardware del Arduino | El microcontrolador no dispone de capacidad suficiente para procesar audio ni inferencias de modelos de lenguaje en tiempo real. | Implementación de la arquitectura Serial Bridge: el procesamiento intensivo se delega al PC y el Arduino actúa exclusivamente como interfaz sensorial y de actuación. |
| Fallo de compilación de PyAudio en Windows | Errores fatales al instalar PyAudio en Python 3.14 por incompatibilidad con la versión y por la ausencia de las herramientas Microsoft C++ Build Tools. | Migración estable a Python 3.12 y reconfiguración del intérprete del entorno de desarrollo (VS Code / Cursor). |
| Desincronización de los entornos virtuales | El IDE mostraba avisos missing-import a pesar de tener las dependencias correctamente instaladas en el venv. | Recarga manual de la caché del IDE y revisión de las rutas del PATH del sistema operativo para alinear los intérpretes activos. |
| Inestabilidad del módulo de micrófono | Los pines del módulo MAX4466 venían sin soldar de fábrica, lo que provocaba contactos intermitentes y la caída del módulo durante el manejo. | Soldadura de los pines header al PCB del módulo, dejando una conexión mecánica y eléctrica robusta. |
| Integración física dentro de la carcasa | El encapsulado generaba problemas de gestión de espacio, riesgo de desconexión de jumpers por dobleces y resonancias acústicas indeseadas. | Planificación previa de la distribución interna, fijación con adhesivo de doble cara y espaciadores, y cortes de precisión en el panel frontal para LCD y micrófono. |
6. Reparto de Tareas y Casos de Uso
6.1. Distribución del trabajo
La asignación de responsabilidades se ha realizado en función de los perfiles e intereses de cada miembro del grupo, garantizando que cada subsistema contara con un responsable principal:
- Hardware — Álvaro y Diego: diseño del circuito, soldadura de los módulos, ensamblaje de la pantalla LCD y del amplificador PAM8403, y validación eléctrica del prototipo.
- Backend en Python — Álvaro: configuración de las API keys, resolución de dependencias (notablemente PyAudio), implementación de la lógica de IA y orquestación del flujo conversacional.
- Frontend en C++ — Álvaro: diseño de la matriz gráfica de expresiones faciales, gestión del puerto COM e implementación de la máquina de estados del Arduino.
- Infraestructura física — David e Iván: construcción de la carcasa, pintura, cortes de precisión en el panel frontal e integración mecánica de los componentes electrónicos.
6.2. Casos de uso y aplicaciones prácticas
Aunque BMO se ha planteado como un prototipo académico, la arquitectura y los principios de diseño aplicados lo hacen extrapolable a tres familias de aplicaciones reales:
- Asistencia de escritorio: consulta rápida de información, gestión de agenda y recordatorios sin necesidad de interactuar con teclados ni pantallas, lo que mejora la concentración del usuario en su tarea principal.
- Educación interactiva: compañero de aprendizaje amigable para la práctica de lectura, comprensión oral o idiomas, especialmente útil en públicos infantiles donde la presencia física aporta engagement.
- Accesibilidad: interfaz operada al cien por cien por voz, particularmente valiosa para personas con movilidad reducida, discapacidad visual o usuarios de edad avanzada para los que las interfaces gráficas convencionales suponen una barrera.
7.Código Software
7.1 Control de Pantalla Arduino y Micrófono
#include <LiquidCrystal.h>
LiquidCrystal lcd(12, 11, 5, 4, 3, 2);
const int micPin = A0;
const int ruidoUmbral = 50;
enum RobotState {
IDLE,
LISTENING,
THINKING,
SPEAKING
};
RobotState currentState = IDLE;
unsigned long previousMillisSpeak = 0;
const long speakInterval = 300;
bool mouthOpen = false;
unsigned long previousMillisThink = 0;
const long thinkInterval = 400;
int thinkFrame = 0;
void setup() {
Serial.begin(9600);
lcd.begin(16, 2);
pinMode(micPin, INPUT);
lcd.clear();
lcd.setCursor(0, 0);
lcd.print(«BMO Iniciando…»);
delay(1500);
Serial.println(«BMO: Arduino Listo.»);
updateLCD();
}
void loop() {
if (Serial.available() > 0) {
char command = Serial.read();
if(command != ‘\n’ && command != ‘\r’) {
switch (command) {
case ‘I’: case ‘i’: currentState = IDLE; updateLCD(); break;
case ‘L’: case ‘l’: currentState = LISTENING; updateLCD(); break;
case ‘T’: case ‘t’: currentState = THINKING; thinkFrame = 0; updateLCD(); break;
case ‘S’: case ‘s’: currentState = SPEAKING; updateLCD(); break;
}
}
}
if (currentState == IDLE) {
unsigned long startMillis = millis();
int signalMax = 0;
int signalMin = 1024;
while (millis() – startMillis < 50) {
int sample = analogRead(micPin);
if (sample > signalMax) {
signalMax = sample;
}
if (sample < signalMin) {
signalMin = sample;
}
}
int peakToPeak = signalMax – signalMin;
if (peakToPeak > ruidoUmbral) {
Serial.println(«RUIDO_DETECTADO»);
delay(1000);
}
}
unsigned long currentMillis = millis();
if (currentState == THINKING) {
if (currentMillis – previousMillisThink >= thinkInterval) {
thinkFrame = (thinkFrame + 1) % 4;
previousMillisThink = currentMillis;
updateLCD();
}
}
if (currentState == SPEAKING) {
if (currentMillis – previousMillisSpeak >= speakInterval) {
mouthOpen = !mouthOpen;
previousMillisSpeak = currentMillis;
updateLCD();
}
}
}
void updateLCD() {
lcd.clear();
switch (currentState) {
case IDLE:
lcd.setCursor(4, 0);
lcd.print(«( ^_^ )»);
lcd.setCursor(2, 1);
lcd.print(«Esperando…»);
break;
case LISTENING:
lcd.setCursor(4, 0);
lcd.print(«( O_O )»);
lcd.setCursor(1, 1);
lcd.print(«Escuchando…»);
break;
case THINKING:
lcd.setCursor(4, 0);
lcd.print(«( -_- )»);
lcd.setCursor(2, 1);
lcd.print(«Pensando»);
for(int i=0; i<thinkFrame; i++) {
lcd.print(«.»);
}
break;
case SPEAKING:
lcd.setCursor(4, 0);
if (mouthOpen) {
lcd.print(«( O_O )»);
} else {
lcd.print(«( O-O )»);
}
lcd.setCursor(3, 1);
lcd.print(«Hablando…»);
break;
}
}
7.2 Control de audio e IA (Python)
7.2.1 ai_module.py (Conexión con la API de Gemini)
import google.generativeai as genai
import os
class AIModule:
def __init__(self, api_key=None):
self.api_key = api_key or os.environ.get(«GEMINI_API_KEY»)
if not self.api_key or self.api_key == ‘TU_CLAVE_API_AQUI’:
print(«[IA] ADVERTENCIA: No se ha configurado una GEMINI_API_KEY válida.»)
self.model = None
self.chat = None
return
genai.configure(api_key=self.api_key)
instrucciones = «Eres BMO, un robot asistente interactivo simpático y útil. Responde siempre de manera breve (1 o 2 frases máximo) y conversacional. No uses formatos complejos como Markdown o listas, ya que tu respuesta será leída en voz alta por un sintetizador de voz.»
self.model = genai.GenerativeModel(‘gemini-flash-latest’, system_instruction=instrucciones)
self.chat = self.model.start_chat(history=[])
def get_response(self, text):
if not self.chat:
return «Error: No tengo configurada mi clave de API. Por favor añádela en main.py.»
try:
print(«[IA] Consultando a Gemini…»)
response = self.chat.send_message(text)
respuesta_limpia = response.text.replace(‘\n’, ‘ ‘).strip()
print(f«[IA] Respuesta obtenida: ‘{respuesta_limpia}'»)
return respuesta_limpia
except Exception as e:
print(f«[IA] Error comunicando con la API: {e}»)
return «Lo siento, tuve un problema procesando tu mensaje.»
}
7.2.2 list_models.py (Script de utilidad no es parte del funcionamiento principal)
import google.generativeai as genai
with open(«main.py», «r», encoding=»utf-8″) as f:
for line in f:
if line.startswith(«GEMINI_API_KEY»):
key = line.split(«=»)[1].strip().strip(«‘»).strip(‘»‘)
break
genai.configure(api_key=key)
print(«Buscando modelos compatibles con tu clave…»)
for m in genai.list_models():
if ‘generateContent’ in m.supported_generation_methods:
print(m.name)
7.2.3 serial_module.py (Comunicación entre el ordenador y el Arduino)
import serial
import time
class BmoSerial:
def __init__(self, port=’COM3′, baudrate=9600):
self.port = port
self.baudrate = baudrate
self.ser = None
def connect(self):
try:
self.ser = serial.Serial(self.port, self.baudrate, timeout=1)
time.sleep(2)
print(f«[Serial] Conectado a BMO en {self.port}»)
return True
except serial.SerialException as e:
print(f«[Serial] Error conectando a {self.port}. Asegúrate de que el puerto es correcto y no está en uso por el IDE de Arduino. Detalle: {e}»)
return False
def send_state(self, state_char):
if self.ser and self.ser.is_open:
try:
self.ser.write(state_char.encode(‘utf-8’))
print(f«[Serial] Comando enviado: {state_char}»)
except serial.SerialException as e:
print(f«[Serial] Error enviando comando: {e}»)
print(«[Serial] Conexión perdida. Intentando reconectar…»)
self.reconnect()
else:
print(«[Serial] Advertencia: Intento de enviar estado pero no hay conexión abierta.»)
self.reconnect()
def read_line(self):
if self.ser and self.ser.is_open and self.ser.in_waiting > 0:
try:
line = self.ser.readline().decode(‘utf-8’).strip()
return line
except Exception as e:
print(f«[Serial] Error leyendo datos: {e}»)
return «»
return «»
def reconnect(self):
self.close()
time.sleep(1)
return self.connect()
def close(self):
if self.ser and self.ser.is_open:
self.ser.close()
print(«[Serial] Conexión cerrada.»)
if __name__ == «__main__»:
print(«=== Iniciando test de comunicación Serial con BMO ===»)
PUERTO_ARDUINO = ‘COM3’
bmo_serial = BmoSerial(port=PUERTO_ARDUINO)
if bmo_serial.connect():
print(«\nIniciando secuencia de prueba de expresiones…»)
secuencia = [
(‘L’, ‘LISTENING’, 4),
(‘T’, ‘THINKING’, 5),
(‘S’, ‘SPEAKING’, 4),
(‘I’, ‘IDLE’, 3)
]
for caracter, nombre, espera in secuencia:
print(f«\n–> Cambiando a estado: {nombre}»)
bmo_serial.send_state(caracter)
time.sleep(espera)
bmo_serial.close()
print(«\n=== Prueba finalizada con éxito ===»)
else:
print(«\n=== No se pudo iniciar la prueba ===»)
7.2.4 stt_module.py (Escucha)
import speech_recognition as sr
class STTModule:
def __init__(self):
self.recognizer = sr.Recognizer()
self.recognizer.pause_threshold = 2.0
def listen(self, language=»es-ES»):
with sr.Microphone() as source:
print(«\n[STT] Ajustando al ruido ambiental…»)
self.recognizer.adjust_for_ambient_noise(source, duration=1)
print(«[STT] Escuchando (habla ahora)…»)
try:
audio = self.recognizer.listen(source, timeout=10, phrase_time_limit=25)
print(«[STT] Procesando audio…»)
texto = self.recognizer.recognize_google(audio, language=language)
print(f«[STT] Texto reconocido: ‘{texto}'»)
return texto
except sr.WaitTimeoutError:
print(«[STT] Tiempo de espera agotado. No se detectó voz.»)
return None
except sr.UnknownValueError:
print(«[STT] No se pudo entender el audio.»)
return None
except sr.RequestError as e:
print(f«[STT] Error de conexión con el servicio de reconocimiento: {e}»)
return None
7.2.5 tts_module.py (Generador de voz)
import pyttsx3
import threading
class TTSModule:
def __init__(self):
pass
def speak(self, text):
print(f«[TTS] Sintetizando voz: ‘{text}'»)
engine = pyttsx3.init()
for voice in engine.getProperty(‘voices’):
if «spanish» in voice.name.lower() or «es» in voice.id.lower():
engine.setProperty(‘voice’, voice.id)
break
engine.setProperty(‘rate’, 160)
engine.setProperty(‘volume’, 1.0)
engine.say(text)
engine.runAndWait()
print(«[TTS] Reproducción finalizada.»)
def speak_async(self, text, callback=None):
def run_tts():
self.speak(text)
if callback:
callback()
thread = threading.Thread(target=run_tts)
thread.start()
7.2.6 main.py (Controlador e inicializador de todos los módulos)
import time
import sys
from serial_module import BmoSerial
from stt_module import STTModule
from ai_module import AIModule
from tts_module import TTSModule
PUERTO_ARDUINO = ‘COM3’
GEMINI_API_KEY = ‘Aquí poner tu propia clave de API’
def main():
print(«=»*50)
print(» INICIANDO ARIB (AI Robot Interaction Bridge) «)
print(«=»*50)
print(«Cargando módulos…»)
bmo_serial = BmoSerial(port=PUERTO_ARDUINO)
stt = STTModule()
ai = AIModule(api_key=GEMINI_API_KEY)
tts = TTSModule()
conexion_exitosa = bmo_serial.connect()
if not conexion_exitosa:
print(«\nADVERTENCIA: Iniciando en modo ‘Solo Software’ (Sin Arduino conectado).»)
print(«\n¡BMO está listo! (Presiona Ctrl+C en cualquier momento para salir)»)
bmo_serial.send_state(‘I’)
try:
while True:
print(«\n[BMO] Esperando a que hagas ruido (palmada, hablar fuerte)…»)
bmo_serial.send_state(‘I’)
trigger_detectado = False
while not trigger_detectado:
linea = bmo_serial.read_line()
if linea == «RUIDO_DETECTADO»:
trigger_detectado = True
print(«\n[BMO] ¡Ruido detectado! Despertando…»)
time.sleep(0.1)
bmo_serial.send_state(‘L’)
user_text = stt.listen()
if user_text:
bmo_serial.send_state(‘T’)
ai_response = ai.get_response(user_text)
bmo_serial.send_state(‘S’)
tts.speak(ai_response)
bmo_serial.send_state(‘I’)
else:
bmo_serial.send_state(‘I’)
time.sleep(0.5)
except KeyboardInterrupt:
print(«\nInterrupción por teclado detectada. Apagando sistema…»)
finally:
bmo_serial.send_state(‘I’)
bmo_serial.close()
print(«Cerebro desconectado. Adiós.»)
if __name__ == «__main__»:
main()
8. Conclusiones y Líneas de Trabajo Futuro
8.1. Conclusiones
El proyecto BMO ha demostrado de forma práctica que es viable construir un asistente robótico con capacidades conversacionales avanzadas a partir de hardware de bajo coste y servicios de IA en la nube. La combinación de la arquitectura Serial Bridge con un modelo de lenguaje de última generación como Gemini 1.5 Flash permite ofrecer una experiencia de usuario fluida, expresiva y empática con un presupuesto muy contenido.
Más allá del logro técnico, el desarrollo ha constituido un ejercicio integral de ingeniería que ha obligado al grupo a coordinar disciplinas tan diversas como la electrónica analógica, la programación de microcontroladores, el desarrollo backend en Python, la integración con APIs de IA y la fabricación física del producto. Esta transversalidad refuerza el valor formativo del proyecto.
Los principales aprendizajes pueden sintetizarse en tres puntos: la importancia de separar adecuadamente las responsabilidades entre hardware y software, el valor de adoptar protocolos de comunicación deliberadamente sencillos para reducir la superficie de error, y la conveniencia de validar cada subsistema de forma aislada antes de abordar la integración global.
8.2. Líneas de trabajo futuro
De cara a próximas iteraciones, el proyecto admite varias evoluciones naturales que mejorarían tanto su autonomía como su utilidad:
Diseñar una carcasa definitiva mediante impresión 3D que mejore la acústica, la ergonomía y la robustez mecánica del prototipo.
Sustituir el Arduino Uno por una placa con WiFi integrado (ESP32) para eliminar la dependencia del PC y dotar al asistente de operación standalone.
Migrar la salida de voz a un servicio de TTS neuronal en la nube (por ejemplo, Google Cloud TTS o Azure Neural Voices) para conseguir una expresividad y naturalidad superiores a las que ofrece pyttsx3.
Incorporar memoria conversacional persistente que permita a BMO recordar el contexto de interacciones pasadas y personalizar sus respuestas con el tiempo.
Añadir una cámara de bajo coste y un modelo de visión multimodal para que el asistente reaccione no solo al sonido sino también a la presencia y a las expresiones del usuario.
Este seria nuestro video explicando el proyecto a fondo.


