CloudIA
Autor: David Rísquez Gómez
🚀 1. Introducción
CloudIA es un ente robótico diseñado para fusionar la Inteligencia Artificial en la nube con la presencia e interacción física. Formalmente, el objetivo de este proyecto es crear un asistente de voz basado en modelos de Inteligencia Artificial modernos que, a su vez, funciona como un altavoz inteligente.
Todo el sistema es impulsado por un microcontrolador ESP32, capaz de conectarse a APIs complejas, soportar flujos de streaming de datos, ejecutar protocolos de WiFi y Bluetooth y coordinar hardware interactivo en tiempo real sin comprometer la memoria ni la experiencia de usuario.
A diferencia de un altavoz comercial estándar, CloudIA se ha diseñado prestando especial atención a la expresividad visual física, lo que permite interpretar su estado de ánimo y respuestas. Además, se han integrado todos los componentes sobre un cuerpo en homenaje a Eva de la película Wall-E.
⚙️ 2. Arquitectura Hardware
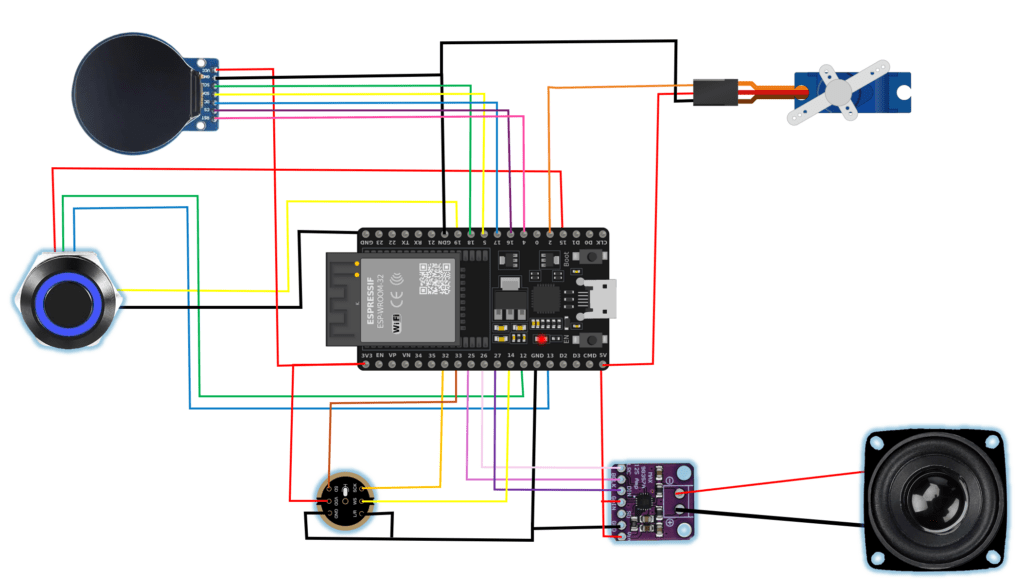
El cerebro del sistema es una placa ESP32-WROOM-D, seleccionada por su arquitectura Dual-Core, imprescindible para manejar en paralelo el procesamiento de red (WiFi/Bluetooth), la lectura de audio y las animaciones visuales. La placa se ha conectado a una base de expansión para facilitar el cableado.
Los «sentidos» de CloudIA se dividen en los siguientes componentes:
- 🕹️ Input de control: Pulsador momentáneo con aro RGB integrado. Configurado en el pin 19 utilizando la resistencia interna
INPUT_PULLDOWNdel ESP32 para evitar el uso de resistencias externas. - 🎤 Oído (Micrófono): Módulo omnidireccional INMP441, conectado mediante el bus I2S para aprovechar el acceso directo a memoria (DMA) y no bloquear el procesador.
- 🔊 Voz (Altavoz): Amplificador MAX98357A (también por bus I2S), conectado a un pequeño altavoz para la salida de texto a voz y la reproducción de música.
- 📺 Expresión Facial: Pantalla TFT GC9A01 redonda controlada por bus SPI.
- 🤖 Expresión Gestual: Servomotor SG90 (controlado por PWM) que permite rotar la cabeza del robot de un lado a otro.
💻 3. Arquitectura Software: RTOS y Documentación de Clases
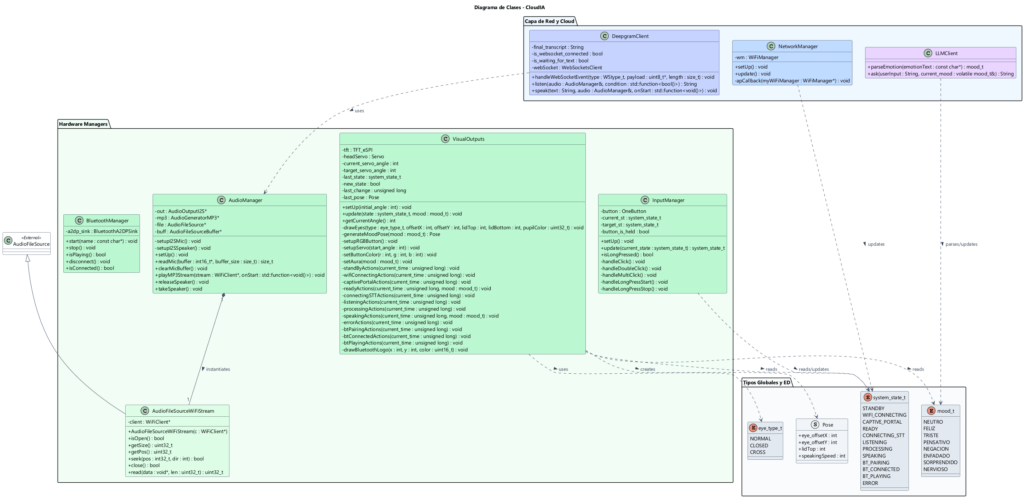
En beneficio de la entendibilidad, modularidad y desacoplamiento, la arquitectura software ha sido diseñado aprovechando los beneficios de la Orientación a Objetos proporcionada por C++. Así, en lugar de desarrollar el proyecto en un único archivo principal monolítico, se ha seguido un patrón basado en managers. De esta forma, cada componente interactúa exclusivamente con el manager encargado de su comportamiento y, desde el punto de vista del software, la utilización de componentes queda completamente encapsulada.
El sistema está gobernado por FreeRTOS, dividiendo el trabajo en tres tareas paralelas ancladas al núcleo 1, dejando el núcleo 0 libre para la conexión WiFi. Además, se le asignó a cada tarea la memoria RAM y prioridad en función de su importancia de cara al funcionamiento del sistema.
| Tarea | Prioridad (FreeRTOS) | Memoria Asignada | Descripción |
|---|---|---|---|
taskControl | Alta (3) | 8 KB | Dirige el flujo de ejecución, efectúa los cambios de estado y toma las decisiones cognitivas. Orquesta los diferentes managers para conseguir el funcionamiento del sistema. |
taskWiFi | Media (Solo en Modo IA – 2) | 8 KB | Asegura la conexión WiFi permanente mediante una evaluación del estado de la conexión cada segundo. |
aestheticTask | Alta (2) | 4 KB | Actualiza la pantalla y mueve el servo en consonancia con el estado de ánimo (Modo IA) o de reproducción (Modo Bluetooth) de forma fluida. |
📂 Documentación de Clases Principales (Managers)
- 🔘
InputManager: Encapsula la lectura de la entrada a través del pulsador. Utiliza la librería OneButton para registrar clicks simples, dobles, triples y pulsaciones largas sin bloquear el código. Traduce las acciones del usuario en peticiones de cambio de estado que serán tomadas por el bucle de control principal. - 🎭
VisualOutputs: Es el «alma» gráfica y física del robot. Gestiona la pantalla TFT, los colores del botón RGB y los PWM del servomotor. Posee la función vitalgenerateMoodPose(), que recibe una emoción y la traduce en variables físicas (nivel de apertura del párpado, posición de las pupilas, velocidad de parpadeo y movimiento del cuello) en función del estado y mood. - 🎧
AudioManager: Encapsula la configuración a bajo nivel de los buses I2S. Lee el búfer de audio del micrófono INMP441 mediante descriptores DMA (funciónreadMic()) y contiene la lógica para decodificar un flujo MP3 (stream) en tiempo real para el amplificador MAX98357A (funciónplayMP3Stream()). - 📡
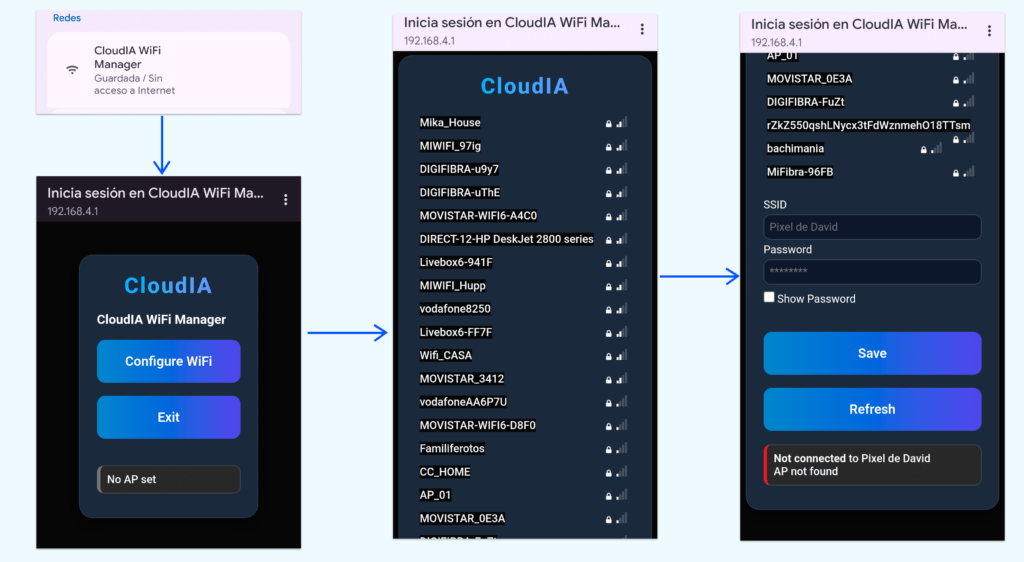
NetworkManager: Abstrae la configuración de la conexión WiFi. Despliega un portal cautivo personalizado (HTML/CSS) en caso de no encontrar redes conocidas, permitiendo al usuario introducir credenciales desde su móvil. Establece que se produzca conexión a redes conocidas en caso de encontrarse en su alcance. - ☁️
DeepgramClient: Cliente dedicado a los servicios de audio en la nube. Posee dos funciones principales:listen()(abre un WebSocket bidireccional enviando audio en streaming directo) yspeak()(realiza una petición HTTPS para recibir audio TTS en streaming). - 🧠
LLMClient: Gestiona la lógica cognitiva mediante la interacción con la API de Groq (modelo LLM Llama-3.1). Envía el mensaje escuchado precedido de un Prompt, obligando a la IA a devolver un objeto JSON con una respuesta y una etiqueta de emoción (ej. FELIZ, ENFADADO, TRISTE). - 📶
BluetoothManager: Emplea la librería BluetoothA2DPSink para transformar a CloudIA en un reproductor de audio comercial. Detecta eventos asíncronos mediante callbacks (reproducción iniciada o pausada) para avisar al sistema visual de que debe activar o detener el ecualizador gráfico en pantalla.
🔄 4. Casos de Uso y Máquina de Estados
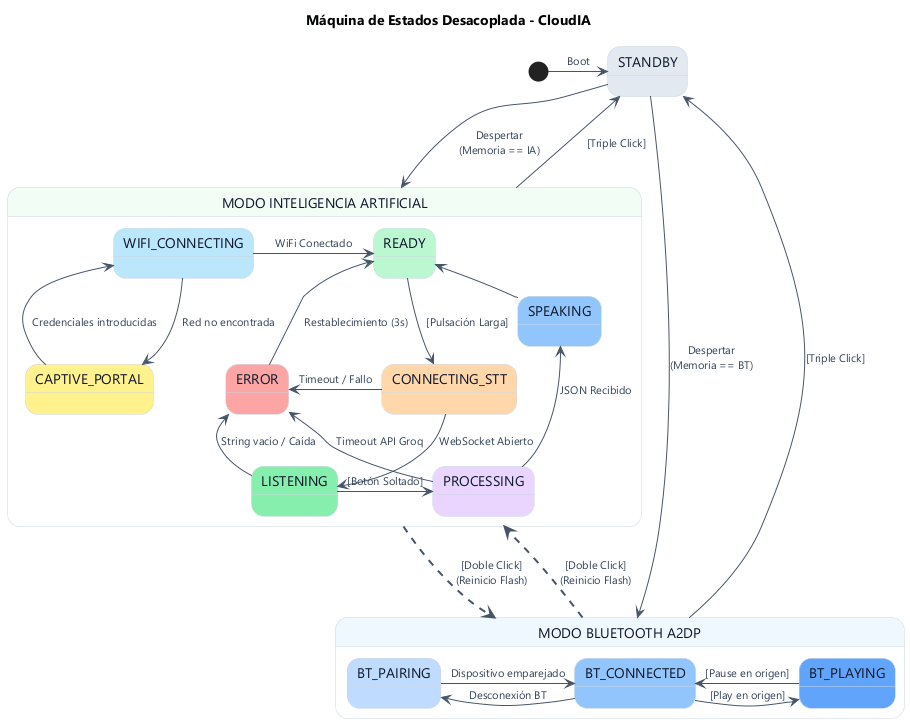
Desde el punto de vista global, CloudIA funciona como una Máquina de Estados Finita. Esto permite al sistema reaccionar a interacciones exitosas y poseer un protocolo determinista ante errores y fallos de conexión. El sistema transiciona entre tres modos genéricos: STANDBY, MODO IA y MODO BLUETOOTH
💤 4.1. Modo STANDBY
Estado de bajo consumo en el que se desactivan la máxima cantidad posible de componentes. La pantalla dibuja los ojos cerrados en un color tenue, se apaga el botón y se paraliza el servomotor. Además, se desactivan los protocolos de red o audio, dedicando los recursos únicamente a detectar una orden de encendido (pulsación de más de 1 segundo).
🤖 4.2. Modo IA
Estado de interacción principal donde el sistema requiere de conexión WiFi para el uso de APIs externas. En este modo, CloudIA queda en estado READY hasta la detección de algún tipo de pulsación sobre el botón. Al detectar una pulsación larga, transiciona a la fase de conexión de audio (CONNECTING_STT), reflejada visualmente con ojos naranjas. Cuando la conexión se ha producido y está lista para escuchar, pasa al estado LISTENING, indicándolo con ojos verdes y barras de ecualización en pantalla. Al soltar el botón, se procesa el texto (PROCESSING) bajo un aspecto de color morado y se responde SPEAKING, de acuerdo a la emoción detectada.
En este proceso, pueden producirse distintos errores que podrían llevar al sistema a un bloqueo. Así, se ha modelado un estado de ERROR, al que se transiciona en caso de que se produzcan alguno de los siguientes:
- 🌐 Ausencia de red conocida (Portal Cautivo): Si al arrancar este modo el sistema no encuentra una red WiFi guardada, se evita que el sistema permanezca buscando una red mediante la creación de un punto de acceso propio (
CAPTIVE_PORTAL). La pantalla informa al usuario para que se conecte a la red del robot e introduzca las nuevas credenciales desde su teléfono móvil. - ⚠️ Fallo de transcripción o silencios: Si durante el proceso de escucha el usuario mantiene pulsado el botón pero no habla, o si ocurre un corte en la red que corrompe el WebSocket con Deepgram, el proceso de Speech-to-Text devuelve una cadena de texto vacía, informando por pantalla del error.
- 🚑 Recuperación desde
ERROR: Si se detecta una transcripción vacía o una desconexión crítica, se transiciona al estadoERROR. En ese momento, la pantalla muestra unos ojos en forma de equis y el anillo LED se ilumina en color rojo. Tras tres segundos, para que el usuario tenga tiempo suficiente de observar el error, el sistema vuelve al estadoREADY, listo para un nuevo intento.
🎵 4.3. Modo BLUETOOTH
CloudIA espera en fase de emparejamiento (BT_PAIRING) hasta vincularse con un dispositivo, pasando entonces al estado BT_CONNECTED. Cuando el dispositivo reproduce algún sonido, se transiciona al estado activo (BT_PLAYING).
Al igual que en el MODO IA, este modo cuenta con un proceso de vigilancia en segundo plano. Si el usuario pausa la música, el sistema retrocede al estado BT_CONNECTED. Además, si se produce una desconexión Bluetooth, la tarea de control hace transicionar al sistema a la fase de emparejamiento, asegurando que CloudIA vuelva a ser visible en la red Bluetooth para nuevos enlaces.
🗺️ Diagrama de Estados (UML)
🧠 5. Modo IA: Pipeline Cognitivo y Gestión Emocional
Este modo recoge el comportamiento principal de CloudIA. El proceso de escucha, razonamiento y respuesta queda completamente encapsulado en un pipeline de comunicación en la nube, que recoge una sucesión ordenada de protocolos para conseguir dichas funcionalidades. Este proceso se divide en tres fases.
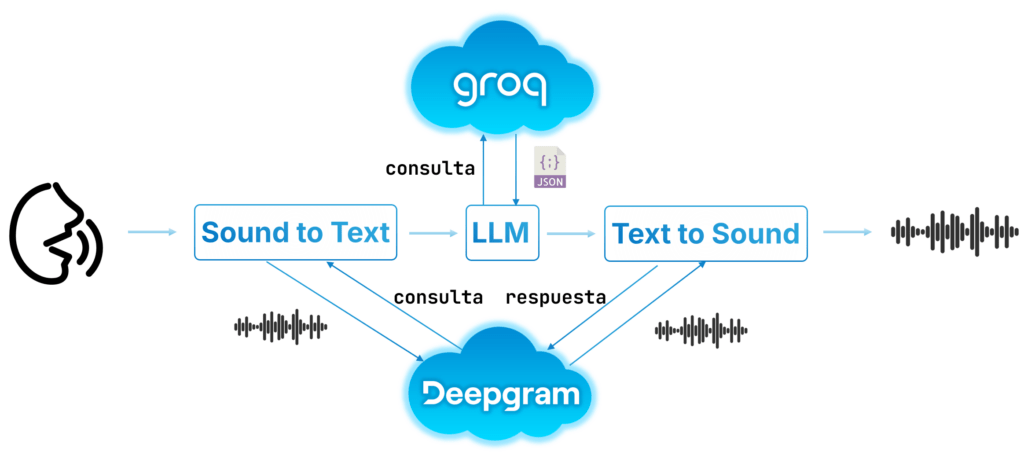
🎙️ 5.1. Fase de Captura y Transcripción
Al mantener presionado el botón principal, el InputManager detecta una pulsación larga y cambia el estado del sistema a CONNECTING_STT. En este momento, el bucle principal utiliza la clase DeepgramClient para abrir un túnel WebSocket (Streaming) con Deepgram.
Una vez establecida la conexión WebSocket bidireccional, el sistema pasa al estado LISTENING, en el que se mantendrá mientras que el botón siga pulsado.
- El
AudioManagerentra en un bucle donde lee los datos del micrófono INMP441 mediante el bus I2S. - Los fragmentos de audio se van almacenando en un buffer circular y se van enviando en streaming a Deepgram empleando el modelo Nova-2.
- Al soltar el botón, se envía un mensaje de control JSON (
{"type": "CloseStream"}) para cerrar el flujo de audio. - Se van recibiendo las transcripciones parciales mediante una función callback asíncrona, y se construye el String definitivo con la petición.
🤔 5.2. Fase Cognitiva y Detección de Emociones
Una vez marcada como definitiva la transcripción, el sistema pasa al estado PROCESSING y se transfiere la responsabilidad a la clase LLMClient. Esta clase realiza una petición HTTPS POST a la API de Groq, uno de los motores de inferencia con menor latencia del mercado, usando el modelo Llama-3.1-8b-instant.
Con el objetivo de dotar a CloudIA de consciencia de su existencia y de personalidad, la petición inyecta una cabecera en el Prompt que le indica a la IA su nombre, creador y contexto. Además, impone que la respuesta ha de ser devuelta en el siguiente formato JSON: {"respuesta": "texto", "emocion": "ETIQUETA"}.
Al recibir la respuesta de Groq, se extrae por un lado el texto de respuesta y por otro el valor de la emoción. La respuesta es devuelta por LLMClient para ser usada en la siguiente fase, mientras que se actualiza la variable global volatile mood_t current_mood con la emoción reconocida. Las emociones mapeadas en el sistema son ocho: NEUTRO, FELIZ, TRISTE, PENSATIVO, NEGACION, ENFADADO, SORPRENDIDO y NERVIOSO.
🎭 5.3. Fase de Síntesis y Reacción Física
La respuesta proporcionada por LLMClient es enviada a través de la API Text-to-sound (TTS) de Deepgram (modelo Aura) solicitando una codificación MP3. Para evitar retrasos, no se espera a descargar el archivo al completo, sino que se utiliza una clase wrapper (AudioFileSourceWiFiStream) que recoge los fragmentos de audio y se los entrega directamente a la librería decodificadora MP3 (AudioGeneratorMP3). Esto permite que el altavoz empiece a sonar en el instante en el que llega el primer paquete de audio, reduciendo los tiempos de espera.
En el momento el que tiene lugar la primera expulsión de audio por el altavoz, se transiciona al estado SPEAKING (mediante callback), de manera que la tarea aestheticTask muestra a CloudIA hablando en el momento exacto en el que empieza a haber sonido. Paralelamente, al haberse establecido el mood actual del robot, la respuesta vendrá acompañada de diferentes reacciones en función de su valor. De este modo, los distintos estados de ánimo tienen asociados valores particulares para los parámetros citados a continuación, que regulan la forma en la que aestheticTask ejecuta la respuesta estética del robot:
| Parámetro Dinámico | Función(es) a la que aplica | Ejemplo de Comportamiento |
|---|---|---|
👄 Apertura de la Boca (mouth_opening) | speakingActions() | Más cerrada para la emoción TRISTE y más abierta de forma aleatoria para el resto. |
🔄 Ángulo del Cuello (target_servo_angle) | generateMoodPose(), speakingActions() | Posición a 135º (mirando a la lejanía) para PENSATIVO, u oscilaciones matemáticas para gesticular la NEGACION. |
👀 Dirección de Pupilas (eye_offsetX, eye_offsetY) | generateMoodPose(), drawEyes() | Cambios aleatorios y rápidos en NERVIOSO o desplazamiento fijo que apunta hacia el cuello en TRISTE. |
😑 Apertura de Párpados (lidTop) | generateMoodPose(), drawEyes() | Cerrados (ceño fruncido) en ENFADADO y completamente abiertos en SORPRENDIDO. |
⚡ Velocidad de Gesticulación (speakingSpeed) | generateMoodPose(), speakingActions() | Movimiento lento (cada 400 ms) en TRISTE o movimientos rápidos (cada 50 ms) para NERVIOSO. |
⭕ Color del Aura (aura_color) | setAura() | Dibujo de una circunferencia en la TFT, para remarcar el estado de ánimo con un color. |

El resultado es una ilusión de que CloudIA cuenta con consciencia realista, siendo capaz responder a conversaciones humanas con gesticulación, voz y cambios de humor en tiempo real.
📱 6. Modo Bluetooth (Altavoz)
El Modo Bluetooth transforma a CloudIA en un altavoz inalámbrico. Aunque el protocolo se delega a la librería externa BluetoothA2DPSink, la monitorización constante del estado de reproducción permitió ofrecer retroalimentación visual en tiempo real.
Cuando el sistema arranca en este modo, la clase BluetoothManager configura el receptor A2DP (Advanced Audio Distribution Profile). Cabe destacar que este manager enruta el flujo de audio hacia el Puerto I2S 1, evitando colisionar con el micrófono, que reside en el Puerto 0. Tras la configuración, el dispositivo se anuncia en la red Bluetooth como «ClaudIA Speaker».
Cuando la máquina se encuentra en alguno de los estados correspondientes al modo Bluetooth, la tarea principal taskControl verifica el estado de la conexión utilizando los métodos isConnected() y isPlaying() del manager. Así, es capaz de transitar entre los distintos estados avalados en este modo:
BT_PAIRING: Ningún dispositivo conectado. El sistema queda a la espera de emparejamiento.BT_CONNECTED: Un dispositivo se ha enlazado con éxito, pero no está emitiendo sonido.BT_PLAYING: Un dispositivo está enlazado con éxito y se está reproduciendo sonido.
El comportamiento visual de CloudIA se modifica en función de los anteriores estados gracias a la aestheticTask, que hace uso del manager VisualOutputs.
BT_PAIRING: Ojos azules en modo búsqueda, acompañados de un logotipo de Bluetooth parpadeante y ráfagas azules en el botón RGB.BT_CONNECTED: Logotipo fijo de color azul, mirada de frente y el anillo LED en azul fijo.BT_PLAYING: Reproduce un ecualizador gráfico compuesto por seis barras verticales para simular los picos de las frecuencias de audio y movimientos aleatorios de cabeza variando entre 80º y 100º.
Cuando el dispositivo deja de emitir sonido, la máquina retrocede a BT_CONNECTED, deteniendo el servo y devolviendo el rostro a la pantalla en cuestión de un par de segundos.
7. Problemas Encontrados y Soluciones
El desarrollo de un sistema embebido con recursos tan limitados para ejecutar tareas de gran carga supuso varios retos. A continuación, se exponen los obstáculos más críticos y las soluciones aplicadas para sortearlos:
| Problema | Impacto en el Sistema | Solución Implementada |
|---|---|---|
| 💥 Límite de RAM por Modos Incompatibles | La decodificación Bluetooth A2DP (~150KB) y los certificados WiFi SSL (~100KB) excedían la RAM de la placa, causando Kernel Panics al activarse simultáneamente. | Reinicio Limpio Invisible: Se guarda el estado en la memoria Flash (Preferences) y se reinicia la placa al cambiar de modo, arrancando con los módulos requeridos para el modo solicitado y el 100% de la RAM disponible. |
| 🔀 Colisión de Puertos I2S | Tanto el micrófono, el amplificador y el la librería Bluetooth intentaban apoderarse del Puerto I2S 0, bloqueando el audio. | Reasignación de Puertos: Se forzó al micrófono a operar en el I2S-0 y el resto de salidas de audio (MP3/Bluetooth) al I2S-1. |
| ⏳ Colapso por Archivos de Audio (TTS) | El MP3 de respuesta completo saturaba la memoria y generaba altas latencias de respuesta. | Audio en Streaming: Creación de la clase AudioFileSourceWiFiStream para interceptar la red y pasar pequeños fragmentos directamente al decodificador hardware. |
| 📉 Ruido en Transcripción (TTS) | El DMA del I2S retenía ruido previo a la pulsación del botón, ensuciando la escucha del modelo STT. | Limpieza de Búfer: Implementación de clearMicBuffer() para leer y descartar la basura justo antes de abrir la conexión WebSocket. |
| 🧊 Congelación de Animaciones Visuales | Las esperas bloqueantes por peticiones web o Timeouts congelaban el movimiento del servo y el parpadeo de los ojos. | Extracción a Tarea Independiente: Aislamiento de la lógica gráfica en la tarea aestheticTask, comunicada vía variables volátiles independientes. |
| 📡 Inestabilidad de STT y TTS por conexión WiFi | La conexión WiFi es determinante para el funcionamiento del streaming del micrófono hacia y desde Deepgram, provocando bloqueos. | Aislamiento de Cores: Ejecución del NetworkManager en el núcleo 0 del procesador y reducción de fragmentación de memoria ajustando búferes a 8KB. |
Aunque este último problema se ve mitigado por la solución adoptada, las limitaciones de hardware del ESP32 impiden garantizar la estabilidad del streaming de audio ante micro-cortes de red superiores a los 400-500 milisegundos.
🎥 8. Vídeo Demostrativo
🔌 9. Componentes del Proyecto (BOM)
| Componente | Descripción | Coste Estimado (€) |
|---|---|---|
| ESP32-WROOM-D + Placa de Expansión | Placa de desarrollo Dual-Core con WiFi/BT | 5,37 € |
| GC9A01 | Pantalla TFT circular de 1.28″ (SPI) | 2,36€ |
| INMP441 | Micrófono I2S omnidireccional | 1,46 € |
| MAX98357A | Módulo Amplificador de audio I2S | 1,16 € |
| Altavoz Magnético 3W | Altavoz genérico de 4 ohmios | 2,71 € |
| Servo SG90 | Micro servomotor de 180º | 1,86 € |
| Botón LED RGB | Pulsador momentáneo con retroiluminación RGB | 2,01 € |
| Material 3D (PLA) | ~50 metros de filamento PLA gris | ~3,00 € |
| Varios | Cables, mini-protoboard | estimado 1,00 € |
| TOTAL | ~ 20,93 € |
📦 Repositorio del Proyecto
Todo el código fuente, la arquitectura de carpetas, los esquemas y la documentación técnica de CloudIA están alojados de forma pública y open-source.